——一个总是被忽视的偏差
回归模型通常并不研究变量间的因果关系(causation),而是仅估计特征和目标变量之间的相关关系(correlation)。然而,当我们试图沿着数据生成过程的反方向进行回归分析时(例如数据生成过程为 



在医学诊断领域,我们常常需要做所谓的反向因果推断(reverse causal inference)。例如图1.中所展示的一个前门混杂因果模型,



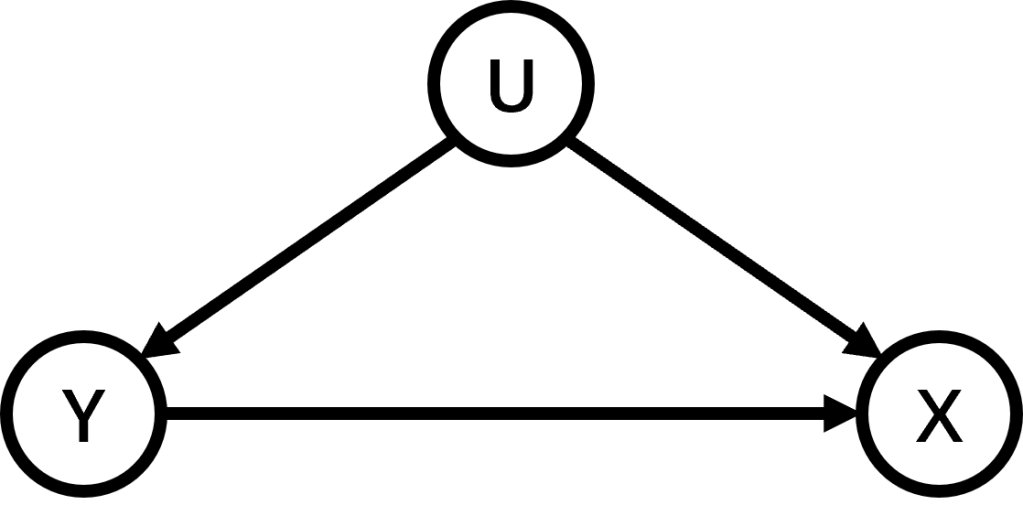
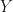 ,结果变量为为
,结果变量为为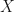 ,混杂因子为。在此例中,结果变量的观测由和共同生成。
,混杂因子为。在此例中,结果变量的观测由和共同生成。 按照图1.中的模型,我们可以假设从原因

其中,



其中,






现在让我们来分析一下,OLS估计下,


接下来,让我们分别计算上式的分子和分母。其中,由于随机误差项


同时,分母

将上面计算的

可以从上式中看出,

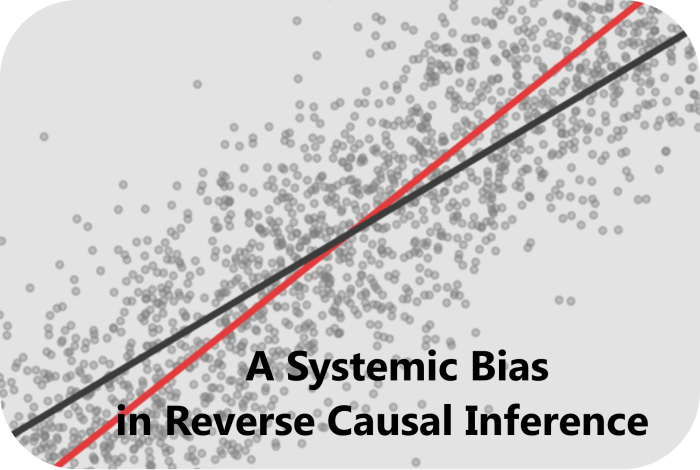
图2. (a)具象化地展示了这种偏差。在图2. (a)中,

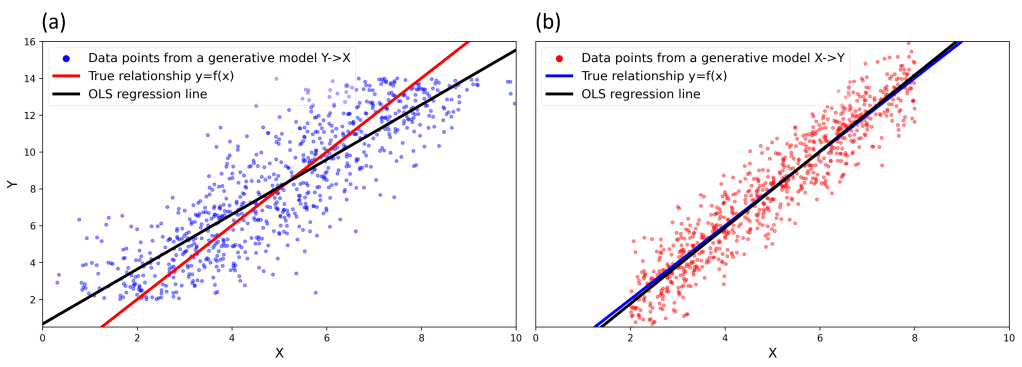
 和
和 的真实关系,以及在各自数据样本上的OLS回归模型。其中,(a)是由生成,红线表示生成关系,也即两个变量间的真实关系,而黑线则代表在此生成模型下
的真实关系,以及在各自数据样本上的OLS回归模型。其中,(a)是由生成,红线表示生成关系,也即两个变量间的真实关系,而黑线则代表在此生成模型下 对
对 的OLS回归。正如前文所试图证明的,这里的OLS回归相对真实生成关系来说是有偏的 。相反地,(b)是由生成,红线表示生成关系,也即两个变量间的真实关系,而黑线则代表在此生成模型下对 的OLS回归,而这里的OLS回归相对真实关系来说是无偏的。
的OLS回归。正如前文所试图证明的,这里的OLS回归相对真实生成关系来说是有偏的 。相反地,(b)是由生成,红线表示生成关系,也即两个变量间的真实关系,而黑线则代表在此生成模型下对 的OLS回归,而这里的OLS回归相对真实关系来说是无偏的。在实际的反向因果推断中,我们并不能明确的知道生成过程的具体参数,那么我们又该如何估计去除掉这个系统性偏差的真实关系呢?让我们尝试从反向因果推断的回归模型


然后,我们可以估计它的方差

联立这个残差项的方差表达式和上文给出的有偏OLS估计


