
An Interpretable Machine Learning Technique for Time-series Analysis
PFFRA is an Interpretable Machine Learning technique to analyse the contribution of features in the frequency domain. This method is inspired by permutation feature importance analysis but aims to quantify and analyse the time-series predictive model’s mechanism from a global perspective.
Source code available here.
Installation and getting started
We currently offer seamless installation with pip.
Simply:
pip install PFFRA
Alternatively, download the current distribution of the package, and run:
pip install .
in the root directory of the decompressed package.
Background
Permutation Feature Importance Analysis
It is important to understand and disclose the most important features that contribute to the predictions through a reasonable measuring scheme, because this knowledge can help machine learning engineers improve model transparency and reveal unwanted behaviours [1].
Permutation feature importance is another model-agnostic method originally applied in Random Forests (RF) [2]. This method measures the feature importance by measuring how much metrics score, e.g., Mean Square Error (MSE), drops when Out-of-Bag (OOB) dataset without a certain feature is used. In practice, the feature which is under-test is replaced with noises instead of directly removing, for example, a common approach to introduce the noise is shuffling the feature values [3][4].
Permutation Feature-based Frequency Response Analysis
Existing IML techniques are not designed to explain time-series machine learning models. In our recent work [5], we propose a new global interpretation technique called Permutation Feature-based Frequency Response Analysis (PF-FRA) to investigate the contribution of interested features in the frequency domain. Briefly, PF-FRA compares frequency responses of the given model based on the permuted dataset. These generated spectrums enable the user to identify the interested features’ contribution to different frequency ranges. In this case, the user may identify if a feature leads to short- or long-term trend in the time-series model’s predictions.
To check more detail about the PF-FRA algorithm, please find it here.
Algorithm
Algorithm: Permutation Feature-based Frequency Response Analysis (PF-FRA)
Input:
Dataset with 
Interested feature:
Time-series model:
Output: Spectrum pair of the model response with and without the interested-feature permutation

1. Train the time-series model 
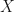
2. Based on the dataset 

3. Generate prediction series 
4. Compute the spectrum of

5. Repeat steps 2 to 4 by substituting other features with their mean values as interested-feature-remained dataset 

6. Compare the spectrum pair of the model response for the two modified datasets in the frequency domain.
Reference
[1] Hooker, Sara, et al. “A benchmark for interpretability methods in deep neural networks.” arXiv preprint arXiv:1806.10758 (2018).
[2] Breiman, Leo. “Random forests.” Machine learning 45.1 (2001): 5-32.
[3] Fisher, Aaron, Cynthia Rudin, and Francesca Dominici. “All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously.” Journal of Machine Learning Research 20.177 (2019): 1-81.[4] Wei, Pengfei, Zhenzhou Lu, and Jingwen Song. “Variable importance analysis: A comprehensive review.” Reliability Engineering & System Safety 142 (2015): 399-432.
[5] Mao, Jianqiao, and Grammenos Ryan. “Interpreting machine learning models for room temperature prediction in non-domestic buildings.” arXiv preprint arXiv:2111.13760 (2021).
