
——基于OLS的线性回归模型参数估计
线性回归模型作为一种被深入研究并且已经广泛应用的数理模型,具有可解释性强、计算复杂度低、适合处理大量数据等优势。其中,普通最小二乘法(Ordinary Least Squares, OLS)则是对线性回归模型进行参数估计的主流方法。相关的研究已经严格地证明,在满足若干基本假设的前提下,普通最小二乘估计量(OLS Estimators)就是线性回归模型的最佳无偏估计量(Best Linear Unbiased Estimator, BLUE)。
回顾上篇,我们如果想找到一个方法对狗剩所“盘算”的预测未来收入的一元线性回归模型进行评估,一个最凭直觉的标准就是衡量狗剩所拟合的直线和所有样本点的距离远近——一个好的模型应当能让所有样本点到直线距离的总和尽量地小,而差的模型这个距离总和则会比较大。图1. a) 和 b)能直观地展现这一点:
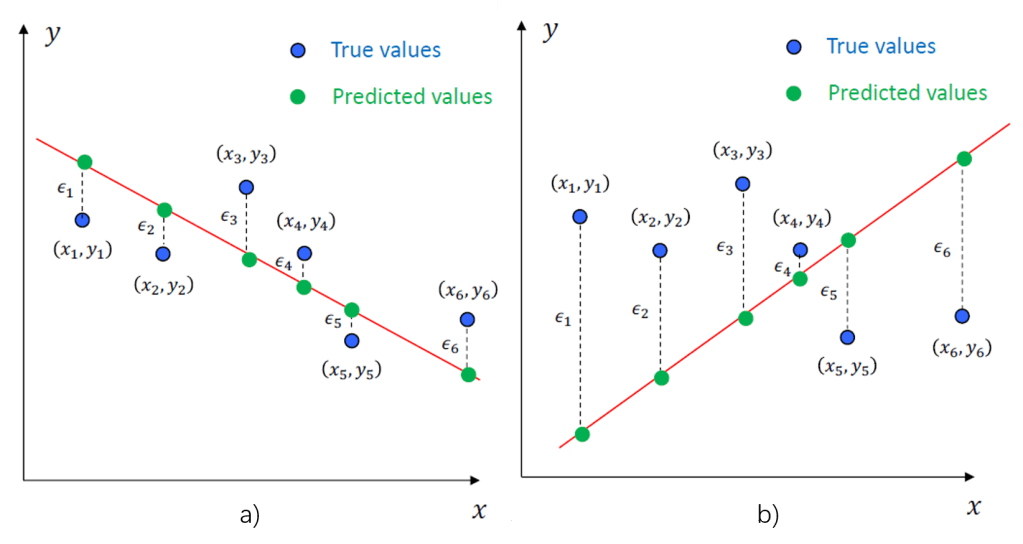
图中,对于每一个样本点




至此,可以说一个


但是,要直接解决这样的一个带有绝对值的目标函数是比较困难的,因为其并不处处可导的。一种比较好的替代办法是对

![{\beta ^*} = \mathop {\arg }\limits_{\hat \beta } \min { \sum\limits_i {{{[{y_i} - ({{\hat \beta }_0} + {{\hat \beta }_1} \cdot {x_i})]}^2}} }](https://s0.wp.com/latex.php?latex=%7B%5Cbeta+%5E%2A%7D+%3D+%5Cmathop+%7B%5Carg+%7D%5Climits_%7B%5Chat+%5Cbeta+%7D+%5Cmin+%7B+%5Csum%5Climits_i+%7B%7B%7B%5B%7By_i%7D+-+%28%7B%7B%5Chat+%5Cbeta+%7D_0%7D+%2B+%7B%7B%5Chat+%5Cbeta+%7D_1%7D+%5Ccdot+%7Bx_i%7D%29%5D%7D%5E2%7D%7D+%7D+&bg=ffffff&fg=111111&s=2&c=20201002)
对于这样一个高中阶段就可以处理的凸优化问题,只需要分别计算使得



进一步地,可以得到

至此,我们就获得了一个残差平方和最小的模型。当模型的参数被估计后,一般需要考虑它的优劣性,即它是否能代表总体参数的真实值。高斯-马尔科夫定理(Gauss-Markov Theorem)已经说明,在经典线性回归的基本假设全部满足的情况下,OLS估计所得到的的估计量是具有最小方差的线性无偏估计量。关于经典线性回归的基本假设,本文由于篇幅有限就不做展开,但对于感兴趣的读者或者正在学习计量经济学的同学,这些假定至关重要——对于不满足基本假定的模型如何检验及如何修正。
比较有趣的一点是进一步探索RSS的含义。基于前面的分析,我们似乎已经解决了全部的问题:指定了评价模型优劣的一般性标准并且找到了能够使得RSS最小的一组模型参数
因此如果我们能找到观测值的浮动(方差)中有多少部分可以被回归模型所解释,就可以以一种更公平地方式评价一个回归模型有多好。很直观地,RSS实际上就是回归模型所不能解释的那部分浮动(方差),而观测值总的方差实际上就是观测值整体的浮动,他们的比值就反应了这些观测值的浮动有多少部分是不能被回归模型解释的。相对地,也就知道了多少部分是能被回归模型解释的。更严谨地,可以定义总体平方和(TSS)为

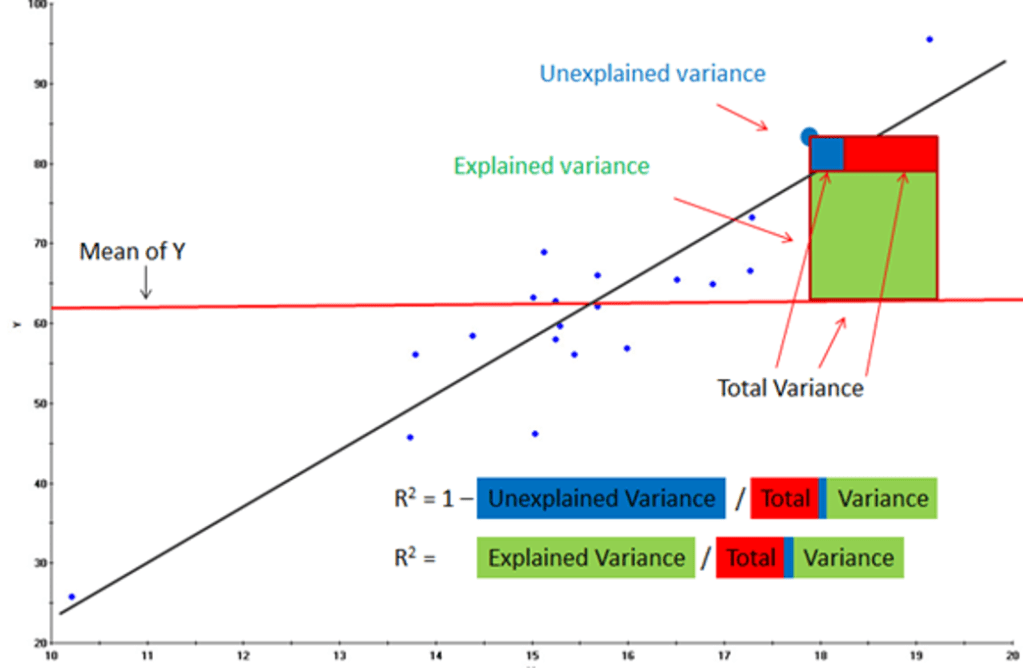
终于,狗剩利用这种方法在计算出它的模型的拟合优度
图3展示了一个有两个自变量的多元线性回归模型。需要注意的是,在这样一个三维空间里,模型的几何表示不再是一条直线,而变成了一个二维平面,观测值和预测值的距离则应当是观测值到回归平面的距离。可以发现,这已经是多元回归模型能可视化展示的极限——对于有三个自变量的多元回归模型,其回归模型的几何表示将成为一个在四维空间中的超平面(体)。
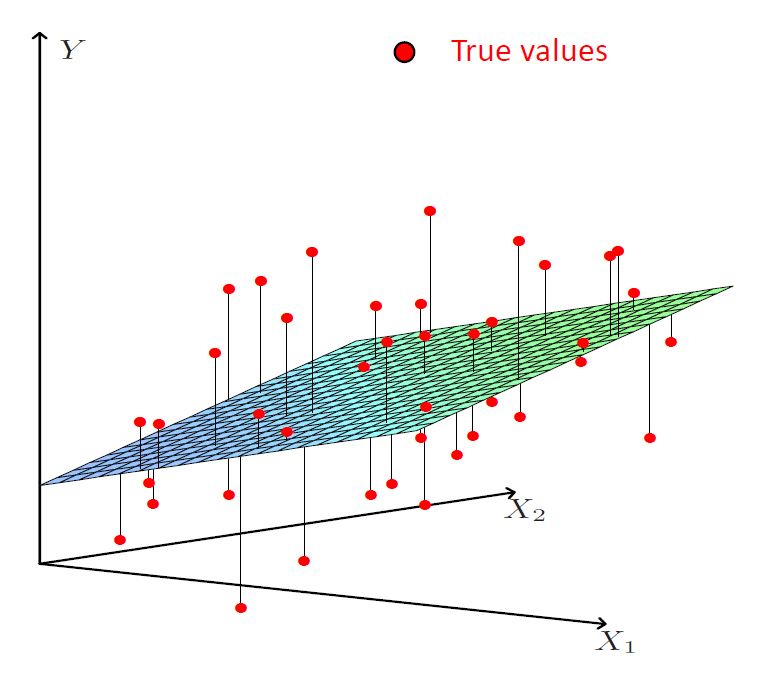
有了上面一元线性回归模型的评价方法和参数估计的基础,要进一步探究多元线性回归,我们只需在其基础上推广到具有多个自变量时即可。类似地,多元线性回归模型可以被表示为:

对于上式中的样本点
![{\bf {x_i}} = {[1,{x_{i,1}},{x_{i,2}},...,{x_{i,m}}]}](https://s0.wp.com/latex.php?latex=%7B%5Cbf+%7Bx_i%7D%7D+%3D+%7B%5B1%2C%7Bx_%7Bi%2C1%7D%7D%2C%7Bx_%7Bi%2C2%7D%7D%2C...%2C%7Bx_%7Bi%2Cm%7D%7D%5D%7D&bg=ffffff&fg=111111&s=1&c=20201002)



![{\bf B} = {[{\beta_0},{\beta_1},...,{\beta_m}]^T}](https://s0.wp.com/latex.php?latex=%7B%5Cbf+B%7D+%3D+%7B%5B%7B%5Cbeta_0%7D%2C%7B%5Cbeta_1%7D%2C...%2C%7B%5Cbeta_m%7D%5D%5ET%7D+&bg=ffffff&fg=111111&s=1&c=20201002)




![{\bf{\hat y}} = {[{\hat {y_1}},{\hat {y_2}},...,{\hat {y_n}}]^T}](https://s0.wp.com/latex.php?latex=%7B%5Cbf%7B%5Chat+y%7D%7D+%3D+%7B%5B%7B%5Chat+%7By_1%7D%7D%2C%7B%5Chat+%7By_2%7D%7D%2C...%2C%7B%5Chat+%7By_n%7D%7D%5D%5ET%7D&bg=ffffff&fg=111111&s=1&c=20201002)


同样地,利用RSS构造损失函数



关于多元线性回归,一个值得讨论的问题是它的拟合优度

显而易见地是,随着自变量数量的增加,RSS将会减小(至少是不变),这也就导致了

其中,


即使我们已经介绍了一元和多元线性回归这两种强大的统计分析方法,但是在实际应用中,因变量和某一些自变量的关系并不总只是线性的,所以它们仍然不能有效地解决自变量和因变量是非线性关系的问题。例如,狗剩喜欢吃苹果,吃一个苹果给他带来的满足度是10,而吃两个苹果给他带来的满足度是18,而你要给狗剩吃3个苹果,他的满足度可能只有20,因为他已经觉得开始撑了,吃到的第三个苹果并不能给狗剩带来和第一个苹果一样的快乐。这就是经济学上著名的边际效用递减规律。如果我们仍然利用吃苹果的数量



